vLLM 是來自 UC Berkeley 的 Woosuk Kwon 和 Zhuohan Li 所製作的推論框架,使用 Paged Attention 技術實現相當驚人的 Token 吞吐量。讓我們一同來探索這個強大框架其背後的原理與用法吧!

(Powered By Microsoft Designer)
首先先來講講前幾天常常提到的 KV Cache,在 Transformer Decoder LM 的 Autoregressive Decoding 裡面,每一次推論都會產生一組 KV 快取。模型必須使用這些 KV 快取來產生下一個 Token,因此會一直被保留在 GPU 記憶體裡面。
然而 KV 快取非常龐大,更糟糕的是如果要做 Batch Inference,這個 KV 快取佔用的記憶體就會翻倍,導致 LLM 即便在有好的硬體設備下,也沒辦法同時進行太多個文本生成。筆者以 24GB GPU 實測 7B 模型進行 2048 Tokens 的文本生成,在 HF Transformers 底下最多只能開到 Batch Size 4 而已。
因此對 LLM Service 而言,最大的瓶頸在 GPU 記憶體。
Paged Attention 這個技術發想自作業系統的分頁記憶體 (Page Memory)。這個演算法將每個序列的 KV 快取切成一個一個區塊 (Blocks),並以此建立區塊表 (Block Table),模型可以透過區塊表來查詢實際的 KV 快取放在哪裡。

(圖源:vLLM)
這樣做的好處在於,KV 快取不再需要使用一段連續記憶體來表示,因此可以被分散的存放在裝置上。而且因為模型是透過查詢區塊表的方式來獲取 KV 快取,所以很自然的也獲得了共享記憶體的能力!記憶體的使用效率大大提昇,減少了許多記憶體的浪費。
我們可以說 Paged Attention 透過查表法的方式解決記憶體瓶頸。

(圖源:vLLM)
從上圖可見 Seq A 與 Seq B 的第一個 Block 共享了同一塊記憶體。因此當兩個序列的某個部份是相似或重複的時候,他們就能共享記憶體以減少消耗。
官方網站提供的 GIF 動畫解釋的相當詳細,但如果跟筆者一樣腦速緩慢的朋友,可以考慮用 ezgif 將 GIF 分解成逐格圖片慢慢看。
透過 pip 安裝 vLLM 套件:
pip install vllm
基本的 Offline Inference 用法如下:
from vllm import LLM, SamplingParams
llm = LLM(model="TheBloke/Llama-2-7b-chat-fp16")
prompts = ["Hello, ", "Hi, ", "Goodbye, "]
sampling_params = SamplingParams(temperature=0.75)
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generate = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generate: {generate!r}")
程式碼相當直觀,多數的生成控制參數都放在 SamplingParams 裡面,可以參考此類別的註解說明。
筆者使用 RTX 3090 簡單測試了一下速度,得到以下結果:
Time Cost: 4.9694
Processed Tokens: 9288
1869 Tokens Per Second
0.5350 ms Per Token
0.53 ms A_A?????
筆者反覆確認了程式碼有沒有寫錯,以及對時間單位定義的認知,確認 1 秒確實是 1000 毫秒,但我還是不敢相信我的眼睛,這個速度真是快到破表!
在 vLLM 裡面,整合了 Continuous Batching 的機制,前一個 Request 推論到一半時,可以中間插入一個新的 Request 一起做推論。如果有 Request 被 Queue 住,也會在任何序列完成時立刻插入。
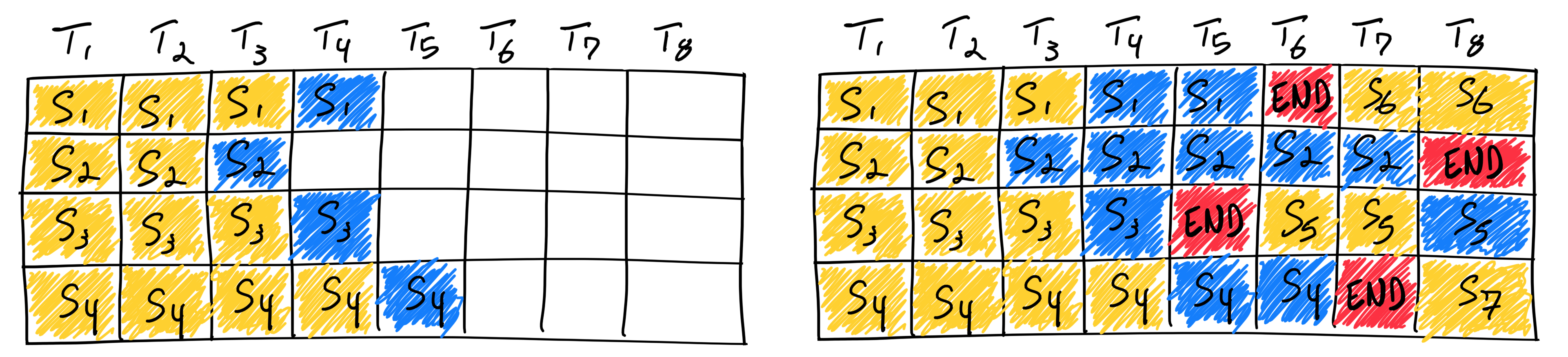
(圖源:Anyscale)
而這個機制被實現在 vLLM 提供的 API Server 裡面,可以透過以下指令啟用:
python -m vllm.entrypoints.api_server \
--model TheBloke/Llama-2-7b-chat-fp16
預設會在 http://localhost:8000 跑一個服務,其後端使用 FastAPI 架設,因此可以到 http://localhost:8000/docs 底下查看說明,但目前他的說明也很簡單:
prompt: the prompt to use for the generation.
stream: whether to stream the results or not.
other fields: the sampling parameters (See SamplingParams for details).
簡單來講就是多了 prompt 跟 stream 兩個參數,剩下的去看 SamplingParams 的說明。我們可以透過以下程式碼進行簡單文本生成:
import json
import requests
url = "http://localhost:8000/generate"
params = {"prompt": "Hello, "}
resp = requests.post(url, json=params)
text = json.loads(resp.text)["text"]
print(text)
也可以使用 Streaming 的方式接收模型輸出,這裡 vLLM 使用 b"\0" 當作 Delimiter,因此 resp.iter_lines() 需要加上額外的參數:
params = {
"prompt": "Hello, ",
"stream": True,
"max_tokens": 256
}
resp = requests.post(url, json=params, stream=True)
prev = ""
for chunk in resp.iter_lines(delimiter=b"\0"):
if not chunk:
continue
text: str = json.loads(chunk)["text"][0]
# 已經顯示過的字串不用再顯示一次
text = text.replace(prev, "")
print(end=text, flush=True)
prev += text
print()
vLLM 決定輸出停止點的方法也相當簡單,只需要指定 stop 列表即可。最後加上一些取樣參數,完整的程式碼大致如下:
prompt = """### USER: 什麼是語言模型?
### ASSISTANT: """
params = {
"prompt": prompt,
"stream": True,
"max_tokens": 2048,
"stop": ["###", "\n\n\n"],
"temperature": 0.75,
"top_k": 50,
"top_p": 0.95,
}
resp = requests.post(url, json=params, stream=True)
prev = ""
for chunk in resp.iter_lines(delimiter=b"\0"):
if not chunk:
continue
text: str = json.loads(chunk)["text"][0]
text = text.replace(prev, "")
print(end=text, flush=True)
prev += text
print()
我們可以用 Multithreading 的方式對 LLM Service 做壓力測試。首先筆者準備了幾份論文原文放在 data 資料夾底下,並切成固定大小的區塊,然後同時發 Requests 出去:
import os
import random
import time
from concurrent.futures import ThreadPoolExecutor
import requests
from transformers import LlamaTokenizerFast as TkCls
# 讀取所有文本資料
txt = str()
for dir_path, _, file_list in os.walk("data"):
for file_name in file_list:
if not file_name.endswith(".tex"):
continue
full_path = os.path.join(dir_path, file_name)
with open(full_path, "rt", encoding="UTF-8") as fp:
txt += fp.read()
# 計算 Tokens 數並切成區塊
tk_path = "TheBloke/Llama-2-7b-chat-fp16"
tk: TkCls = TkCls.from_pretrained(tk_path)
tokens = tk.encode(txt)
print(len(tokens))
# 每個 Chunk 長度 512
# Slide Window 長度 256
n, m = 512, 256
prompts = []
for i in range(0, len(tokens) - n, m):
text = tk.decode(tokens[i : i + n])
prompts.append(text)
# 隨機取 128 個 Chunks
random.shuffle(prompts)
prompts = prompts[:128]
print(len(prompts))
url = "http://localhost:8000/generate"
# 定義呼叫 API 的函式
def process(args):
prompt_id, prompt = args
print(f"Prompt {prompt_id} Begin")
params = {
"prompt": prompt,
"max_tokens": n,
"ignore_eos": True
}
delta = time.perf_counter()
requests.post(url, json=params)
delta = time.perf_counter() - delta
print(f"Thread {prompt_id} Done, Time Cost {delta:.4f}")
# 使用 16 個 Threads 執行
delta = time.perf_counter()
with ThreadPoolExecutor(max_workers=16) as executor:
executor.map(process, enumerate(prompts))
delta = time.perf_counter() - delta
print(f"Total Time Cost: {delta:.4f}")
可以嘗試去調整裡面的一些數值,感受一下 vLLM 處理速度的差異。因為透過 API 呼叫會包含一些網路傳輸延遲,因此速度大多會比 Offline Inference 還要慢。但是真實的使用情境通常也是透過網路呼叫,因此測出來的速度會更貼近實際情況。
我們昨天測試 HF Transformers 同時做 72 筆推論,平均每個 Token 花費 1.23 毫秒,在這裡使用相同的方式測量一下 vLLM 的速度:
import time
from vllm import LLM, SamplingParams
llm = LLM(model="Models/Llama-2-7b-chat-fp16")
prompts = [""] * 72 # 同時推論 72 筆
sampling_params = SamplingParams(ignore_eos=True, max_tokens=128)
delta = time.perf_counter()
outputs = llm.generate(prompts, sampling_params)
delta = time.perf_counter() - delta
total = sum([len(out.prompt_token_ids) for out in outputs])
total += sum([len(out.outputs[0].token_ids) for out in outputs])
tps = total / delta
spt = delta / total * 1000
print(f"Time Cost: {delta:.4f}")
print(f"Processed Tokens: {total}")
print(f"{tps:.0f} Tokens Per Second")
print(f"{spt:.4f} ms Per Token")
最後結果如前面所述,平均每個 Token 花費 0.53 毫秒。但昨天 HF Transformers 測到 73 筆推論就會 OOM 了,現在我們來測試看看 vLLM 跑 144 筆如何:
Time Cost: 8.9559
Processed Tokens: 18576
2074 Tokens Per Second
0.4821 ms Per Token
wow 真是快的跟子彈列車一樣,不僅沒有 OOM 還變得更快了!
我們可以回頭測試一下如果只推論一個 Sample 的話,與其他框架的比較:
HF FP16 - 27 ms
ggml FP16 - 20 ms
vLLM FP16 - 18 ms
以單筆推論來說,與 llama.cpp 在伯仲之間,但 vLLM 的優勢就在於能夠同時推論。
接著比較一下長序列生成的速度:
HF 4 * 2048 - 8.24 ms
vLLM 4 * 2048 - 5.63 ms
vLLM 8 * 2048 - 3.07 ms
vLLM 4 * 4096 - 6.67 ms
vLLM 8 * 4096 - 5.45 ms
當生成長度變長之後,速度明顯慢了很多,但是依然快速而且沒有 OOM。
最大的硬傷是對量化的支援還不是很廣泛,目前只支援 AWQ 量化,多數情況我們都只能以 FP16 進行推論,因此單張 24GB 顯卡完全無法操作 13B 參數量以上的模型。雖然量化需求已經被開發團隊納入 Roadmap 裡面,但是這 Issue 從六月底高懸到現在都還沒完成 🥲
但如果你有多顯卡,那 vLLM 鐵定是個超棒的選擇!請參考分散式推論的文件。
使用 FP16 部署模型的成本實在太高了!雖然 vLLM 的 Token 吞吐量實在高的驚人,但是 No Quantization No Life,想要部署大一點的模型勢必需要更多顯卡,或者尋求其他框架。這時,又是那張神秘笑臉出手了!來自 Hugging Face 團隊開發的 Text Generation Inference 套件,支援既有的量化技術,並率先整合了 Paged Attention 機制,拯救了大眾蒼生的 GPU 記憶體與荷包 💸
明天就來介紹 TGI 吧!

